If anyone is actually reading these, apologies for not posting this sooner. My work became busier and my baby became a toddler, so my free time has decreased dramatically of late.
Part 3: Scaling
From image to pixel coordinates
Let’s keep this short, since it’s a pretty simple concept. In the last blog post, we took three-dimensional coordinates in the frame of reference of the camera, and transformed them into two-dimensional coordinates in the frame of reference of the sensor, i.e. what I call “image coordinates”. The last step sends image coordinates, which are in real-world units such as meters, into pixel coordinates, which are in units of pixels. The difference between image and pixel coordinates is shown in the figure below.
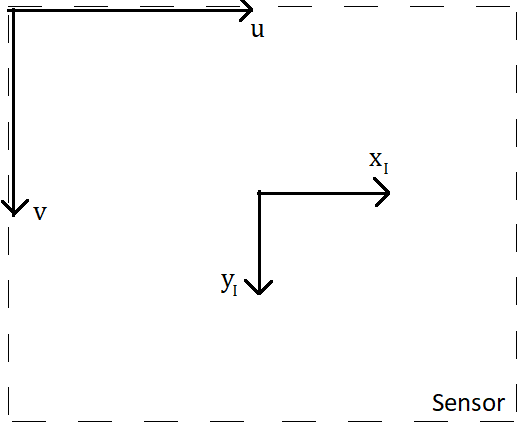
The image-to-pixel coordinate transformation needs to first scale the image coordinates into pixel units, and then needs to translate the result so that the origin is at the top left of the sensor. The translation needs to happen because, for computer memory reasons, images are universally indexed so that (0,0) is at the top left. This operation is conveniently written as a matrix multiplication in homogeneous coordinates:
where and
are the pixel coordinates,
and
are the scaling factors, and
and
are added translation terms.
A source of confusion for me was always units, so let’s try to keep the units clear. and
are in units of distance, i.e. meters or millimeters,
and
are in units of pixels per distance, i.e. pixels/m, and
and
are in units of pixels. So we have a matrix where the units of individual elements are different, which is a consequence of using homogeneous coordinates to represent the transformation.
A brief note on the physical meaning of the values in the scaling and translation matrix: and
are almost always equal, and physically represent the horizontal and vertical pixel density of the sensor. To obtain them from a datasheet, you can divide the number of horizontal and vertical pixels by sensor width and height.
and
are the horizontal and vertical pixel locations of the image center. Usually, these two values will be half of the horizontal and half of the vertical number of pixels, respectively. This is valid for the vast majority of practical applications, but there are some circumstances where the lens isn’t centered with respect to the sensor, like in sensor-shift image stabilization techniques.
However, in nearly all circumstances, the camera’s intrinsic properties (the parameters in the scaling and translation matrix, along with the lens’s focal length) are estimated via a process called camera calibration rather than read off from datasheets. Manufacturing tolerances can mean that what’s on the datasheet isn’t the true value in practice, so calibration is usually performed to obtain the true values, and camera calibration also corrects for lens distortion. I might write a blog post in the future about the basics of camera calibration.
One final practical note: when working with images programmatically, remember that when images are stored in memory as a two-dimensional array, the rows correspond to the y coordinate, and the columns correspond to the x coordinate. Some people (myself included) tend to intuitively think “rows, columns, x, y”, but it’s actually the other way around! Keeping this in mind might save you some pain when going from real-world to pixel coordinates one day.
Putting it all together
Now that we have the final part of our camera model, we can write a single equation which combines all of the transformation matrices, from world coordinates all the way to pixel coordinates:
Note that there is a conversion into non-homogeneous coordinates required for this equation to work (). The first and second matrices on the right hand side are often written as a single matrix:
where and
are the focal length in pixel units. In this way, everything in the matrix has the same units: pixels. The first matrix on the left is called the camera intrinsic matrix, or calibration matrix, and sometimes given the symbol
. The second matrix on the left is called the camera extrinsic matrix.
The intrinsic matrix is more generally written with a skew term, i.e.
where the has the effect of making
scale with
as well as
, which introduces a shearing effect to the transformation. However, in all but specific use-cases, the skew term is close to zero.
Conclusion
This completes the projective camera model. I want to finish by mentioning that the projection part of the projective camera model is only one possible projection, for rectilinear lenses. Other types of lenses, for example telecentric, fisheye, or tilt-shift lenses have different projections. The projective camera model, however, is valid for the most common lenses used in photography and machine vision.
Part 1: Transformation - here
Part 2: Projection - here
Part 3: Scaling - You’re already here!